文章目录:
环境配置与 "hello OS!"
1 环境配置与 "hello OS!"
前言
上的是武大网安院严老师的课头。使用的教材是 Orange's 啥啥的那本书。因为第一次课配环境血压飙的有点快,所以开个帖来记录实验过程。
文章里包含大量指向有用文档的超链接,但是都是夹在文字中的,长这样(不用点,只是演示一下长什么样)。看起来不明显,需要仔细识别。后续可能会考虑改进一下,把链接摆在明显的位置,或是换一个主题。
本人的博客向来是话比较多的,因为个人倾向于把所有想到的东西全部写进来。望多多包涵。
随课持续更新中。也可能开一篇新的文章。
说起来,我对这篇博客的定位其实不是特别的明朗。我并不清楚自己到底想写出一篇什么样的东西来。
事实上,如果只是想记录实验步骤和课后习题什么的答案,去年已经有大佬写过了,而且人家的可读性、排版、完成度等也要远远优于我。
因此,我可能更倾向于把我的文章定位为比较随性的、实验过程中发现的有趣的、试图详细理解研究的问题的记录随笔。
因为比较笨,所以我写 acm
题解时大多数时候会默认读者和我一样笨,然后把整个思考过程的过程都很啰嗦地写出来。我暑假语雀更了上万字,不过群友似乎不怎么看得下去。其实说白了,就是我不太擅长整理和精炼语言。
这个不太好的习惯被我延续到了 OS 实验的博客里。因此这对于只打算看个结果自己想和参考下操作的朋友不是特别的友好。我会在更新的过程中慢慢改进的。
1.1 虚拟机平台与操作系统选择
1.1.1 操作系统
根据老师的说法,64 位系统编译 32 位程序比较麻烦,而且有些东西不一样,折腾起来可能很麻烦,所以建议使用 32 位的操作系统。Ubuntu 版本中带有 i386 的,就是 32 位的。
可以在清华源下载想要的系统光驱。16 往前的才有 i386。也可以去别的地方,无所谓。
我使用的是 ubuntu-16.04.6-desktop-i386。下个 torrent 文件用迅雷下就行,蛮快的。
1.1.2 虚拟机平台
关于虚拟机平台,老师推荐 Virtual Box,因为它开源免费,当然它 bug
也很多;VMware
也是推荐选项,它更稳定,不过大多数都是盗版,不排除出现一些难以解决的问题。老师不推荐我们使用
wsl。wsl 确实蛋疼,没有 service 也没有 systemctl,之前装 mysql
研究了半天才找到怎么开启服务。
周围有好多大佬用的奇奇怪怪的非 desktop 的 linux,看着好帅,我比较菜,就算了吧。
我相对熟悉的是 VMware。当然我也试了一下 Virtual Box,但是折腾半天虚拟机一直卡在启动页面打不开,就不想用了。
1.2 一些"无关紧要"的前置准备
1.2.1 修改软件源到镜像站
之前做过很多次的事情。这里我修改的是清华源,参考这里。
1 | # 先备份一下 |
注意,如果在 sudo apt update
后提示安全证书问题,你可以把 sources.list 里的 https 全部改成 http。
1.2.2 安装 VMware tools 与设置共享文件夹
这里只记录下我具体做了什么,因为我也不知道我在干什么。我用的是
VMware® Workstation 16 Pro。怎么搞到的就不说了。
我先设置的是共享文件夹。在 "虚拟机 -> 设置 -> 选项 -> 共享文件夹"。改成永久启用,然后添加主机上的一个路径。确认之后,类似 wsl2,你就可以通过 /mnt/hgfs 访问主机上的这个文件夹了。
理论上讲这一步最好是重装完 tools 再来做的,但是我提前做了,不清楚会不会有什么影响,所以我将其记录下来作为参考。
但此时我还是不能共享剪切板。所以我重启了一下,然后在菜单栏的虚拟机选项卡里的 "重新安装 VMware tools" 就变黑了。点一下,它大概会把那些东西以一个虚拟光盘的样子挂给你。(因为路径显示的是 /mnt/xxx,所以我猜是挂载的什么玩意)
然后把中间那个 tar.gz 格式的文件复制到 home 目录下,解压出来。不建议直接在那个目录下解压,一个是没有权限,一个是我不知道会发生什么,也不排除本来就是只读的。
然后在解压出来的 VMware-tools-distrib 里打开 terminal,运行
sudo ./vmware-install.pl。
然后我就全程回车保持默认,反正也看不懂。
注意,重装过程中的所有 overwrite 选项都是默认 no,个人是建议全部输入 yes。
然后就好了,然后就可以共享剪切板了。声明一下:如果你还没好,我也不太懂,因为我确实不知道这个安装程序是在干什么。
重装了 tools 后,原来设置的共享文件夹找不到了。所以你需要再删掉重新添加一次。用不用重启我忘了。
我装完 VM tools 之后 VMware 偶尔会出现半分钟左右的莫名奇妙的无响应,不知道在加载什么东西。且这段时间里我主机无法使用复制黏贴功能。不知道有没有遇到相同问题的大佬指导一下。我用的是 VMware® Workstation 16 Pro 16.1.2 build-17966106。
1.2.3 为 github 账户添加新的 ssh key
我有三个虚拟机和一个主机,所以我的 github 账户有四个
key。
当然这个只是个人习惯,完全没打算用远端仓库或是习惯直接输入账号密码的可以无视这部分。
需要注意的是,出于安全上的考虑,过去很多教程里生成 key 的方式不再被支持了。
可以参考官方的指南。
因为我 ssh 用的不多,基本上是每个机子只用同一个 key 到处连,所以没有管 ssh-agent。生成完直接看下一节的添加就行。
也可以参考这个博客。too much 教程,这里就不扯皮了。
1.2.4 zsh oh-my-zsh 相关配置
老师说你们别折腾什么中文输入法,说有人折腾了半天结果把系统搞崩了,最后重装虚拟机。中文输入法确实没有必要,但是 zsh 和 oh-my-zsh 必须要有!(暴论
好吧这个依然是个人习惯。
首先是安装 zsh,很简单 sudo apt install zsh。
问题在于怎么设置 zsh 为默认终端。这个东西这个版本上不能直接
chsh -s /bin/zsh,要在 gnome terminal
的图形化界面里面手动修改。
需要注意的是它的界面和平常用的 windows 不太一样。当终端在前台运行时,桌面左上角会有一个 terminal 的字样,光标移动到它上面,才会出现我们平常见的菜单栏。Terminal -> Preferences -> Profiles,可以直接改原来的这个配置,也可以建一个新的,但是要记得改下面的 profile used when launching a new terminal。
把 profile 里 run a custom command install of my shell 勾上,写上 zsh。顺便把下面的 exit 效果设置成退出终端,体验就和 chsh 基本一致了。
然后自然是要安装 oh-my-zsh。以前小乖乖的游记的时候我用的是改 host 的方式。其实没有必要。我们可以借助国内的镜像。
我们知道这个 oh-my-zsh 是开源的。之所以直接用官网给的安装链接安装不了,是因为 raw.github.com 上不去。那我们直接把这个文件下载下来不久行了。
当然我是连 github 本身也上不去的,所以我选择的是直接使用 gitee 上的镜像。
首先把 /tools/install.sh 搞下来。直接 clone 整个项目或是 wget 之类的都行。
然后打开来看一眼,它告诉你可以执行的时候加上 REMOTE 参数来指定源。指定源来跑就行了。我用的是 ssh,用 http 也一样
1 | # You can tweak the install behavior by setting variables when running the script. For |
弄完后,可以尝试添加一些插件。比如 zsh-syntax-highlighting。
照着它的文档弄就行了。我们装了 ohmyzsh,所以按它教的 ohmyzsh 安装插件的方式来装。
1.3 实验环境配置
1.3.1 Bochs 安装
Bochs 是个模拟器。教材用的是 Bochs,我也不会 Qemu,所以这里用 Bochs。后续可能会考虑看一下 Qemu。
P.S. 模拟器和虚拟机是有很大区别的。模拟器的所有指令都需要经过软件的模拟,也因此它可以跑另一种 CPU 架构下的系统。而个人理解的虚拟化强调的是物理资源的抽象和分配。具体的可以百度 Formal Requirements for Virtualizable Third Generation Architectures 这篇论文了解。当然这和这个实验没有任何关系,我们并不是在研究虚拟化技术,我们研究的是如何实现一个简单的操作系统。
Bochs 可以从官方网站上下载。似乎需要翻墙,各显神通吧。但是我自己在尝试下载的时候,找了半天下载入口。
其实你需要点 Get Bochs -> see all release,然后会跳转到这里。在这里下载 tar.gz 格式的安装包。用共享文件夹或是别的手段搞到虚拟机里。因为我们后续需要使用一些特殊的 configure 选项,所以要下载源码手动编译。
编译的过程可以参考官方文档,上面也写有各个参数的详细意义。
1 | # 安装依赖。虽然说 make 的时候再根据报错来装也可以。 |
P.S. 安装完成后,根据文档的 3.4.1.3,文件的默认目录是 /usr/local/xxx。在后续修改 bochsrc 时会用到 /usr/local/share/bochs 这个目录。
1.3.2 nasm 安装
本实验使用 nasm 来编译汇编源码。直接
sudo apt install nasm 即可。
1.4 Hello OS!
1.4.1 随书源码下载
这本书是由随书源码的。osfs00是这些源码的总目录和随书光碟。课上到哪就去对应的链接里找源码,比如这一节的。老师也会下载了丢在群里,可以用共享文件夹传到虚拟机里。
可以 clone 下来后修改下 boshsrc 直接 make,因为它有一个写好的 makefile。下面我们不用它的 makefile,一步一步手动进行,先熟悉一下。
1.4.2 我们要做什么?
计算机加电时,首先执行的是 BIOS。这是集成在硬件(芯片)中的程序,它会完成基本的 IO 初始化和硬件自检,然后运行系统引导程序,将 OS 装载到 ram 中,并将计算机控制权交给 OS。
或者我们可以说,它的功能是:初始化硬件平台和提供硬件的软件抽象,引导操作系统启动。
我们接下来实现的,其实是操作系统的一个部分:一个引导程序(OS Boot Loader)。在平时,boot loader 的功能是将 OS kernel 装载到内存中。但是我们现在还搞不出内核这种复杂的东西。
因此,在本次实验中,我们其实是利用 Boot Loader 来跑一段简单的汇编程序。在这个过程中体验 PC 机启动和操作系统的初始化过程。
1.4.3 制作一张空白软盘
首先我们需要一张空白的虚拟软盘。Bochs 为我们提供了一个方便的虚拟光驱创建工具 bximage。相关的参数等可以在这里查到。
直接运行 bximage,会有一个交互界面。根据提示一步一步进行就行了。我们需要的是一个软盘(fd, floppy image),其余部分可以全部保持默认。你也可以改名字。
创建完成后,它会有提示,比如:The following line should appear in your bochsrc: floppya: image="b.img", status=inserted。
后面修改 bochsrc 的时候要用到。
根据文档,你也可以直接用指令生成这个软盘而不是进入交互界面:(从 xygg 的实验报告里 copy 出来的)
1 | bximage -func=create -fd=1.44M -q a.img |
当然你也可以不自己生成,直接从随书源码里的 a.img.gz
解压出来。
1.4.4 写入引导程序
引导软盘上装载的是引导程序,重点在程序。在本实验中,是由一段神奇短小的汇编代码实现的,那段代码我们后面再来分析。这里先拿随书源码中现成的 boot.asm,来制作一张引导软盘。
首先编译 nasm boot.asm -o boot.bin。
然后运行下面的指令:dd if=boot.bin of=a.img bs=512 count=1 conv=notrunc。
dd 是 linux 中自带的指令,一般用于文件的复制、读写、转码等,它可以加入很多的参数。
在这个指令中,if 和 of 指定的是输入文件和输出文件,不指定时默认是标准输出。bs 是块的大小,count 是块的数量。notrunc 的意思是 no truncate,非截断。我们这里需要的是一个完整的软盘,自然是不能让它截断的。
(虽然其实这个实验里,后面的部分并不会用上,截断了也不是不能跑)
P.S. 什么是截断?举例而言:echo "hello" > a.txt,如果 a.txt 本来是个很大的文件,那它的大小会被改变,只剩 "hello" 占的大小(当然实际可能是一个块的大小,这里只是举个例子)。截断的意思大概是,把大于输入的部分全部"删掉",把输出文件"截"剩下输入的大小。
总之,现在我们就得到了一张引导盘。可以开始准备跑起来了。
1.4.4 boshsrc 修改
由于教材比较古老,所以随书源码的 boshsrc 有些配置已经失效了,需要进行修改。
最重要的是 romimage 和 vgaromimage 的文件目录。
最简单的判断路径对不对的方法是直接 cd 进去看看有没有这个文件。
这里的 romimage 指的是 BIOS 的 image,是随 bochs 分发的。根据文档,它的默认位置应该是:/usr/local/share/bochs/BIOS-bochs-latest。
事实上这个文件也是部署的时候从你下载的源码包里面 copy 过去的,所以你直接在你下下来的解压的文件夹里也能找到这个 image,例如 bochs-2.7/bios/BIOS-bochs-latest。
如果你实在找不到,也可以
sudo find / -name "BIOS-bochs-latest"。
至于 vgabios,直接 whereis vgabios
就可以找到(在前面安装依赖时,它是直接 apt install 的)。
软盘部分在创建后 bximage 会给出提示,我们前面提到过了。
最后面的 keyboard_mapping 部分要注释掉。这个东西 15 年就有个 issue 了。应该是个已经被抛弃的写法。
PPT 上还提到了 display_library。可以参考文档的 4.3.3。似乎与模拟器的显示有关。根据文档,不加的话默认选的应该也是 sdl(我们 configure 的参数也是 sdl),不过我还是加上了。
1 | # how much memory the emulated machine will have |
1.4.5 运行效果及部分常见报错
接下来就可以直接运行了 bochs -f bochsrc(也可以直接
bochs,只要在同一个目录内)。
因为前面开了 debug,所以你要在交互窗口上输入 'c',让它继续运行。运行结果是,在弹出来的窗口上看到一行红色的 "Hello, OS world!"。
报错 1:couldn't open ROM image file。你的 bochsrc 里面路径错了需要检查一下。
报错 2:其实严格来说不是报错。如果你发现你的第一条指令不是 jmp,而是
add [bx+si],al(其实这条指令的机器码是0000)(我们开了
debug,在输入 c
的时候会注意到的),之类的很奇怪的指令,还一直报奇怪的数学运算错误之类的,那就是你的
rom image 选错了。那个是随 bochs 分发的 BIOS image,而不是你自己的创的
a.img。具体可以看前面 1.4.4。
1.5 hello os 源码分析与调试
1.5.1 无关紧要的前置准备
恭喜,我们运行了 hello os。但是别急,我们还要研究一下这个汇编程序在干什么。
在研究的过程中,我们可能会需要修改这个 boot.asm 来测试产生的变化。但是,我们每次修改都要走一遍上面的流程:编译 - 写入 - 运行(虽然其实只是 cv 三条指令)。我们可以写个脚本,让这个过程自动化。
你可能注意到了随书源码里的 makefile。你可以直接在上面改,也可以写个新的脚本。
其实那个 makefile 是可以直接用的,每次 make 解压一个新的 a.img
出来也是更合理的做法。当然,本实验中每次挂载进去的都是同样大小的内容,所以解不解压并没有什么影响。
草了,它给的那个 a.img.gz 里的 a.img 根本就不是一个空白软盘。它本来就是烧过的。所以你会发现直接注释掉 dw 0xaa55 它照样能跑,因为你写入 boot.bin 的方式是非截断的,原本就烧在里面的 0xaa55 并不会被你覆盖掉。
如果你不想像我下面这样直接生成一个新的软盘,应该删掉原来的 a.img.gz,自己用 bximage 弄出一个空白 a.img 后重新压缩成 a.img.gz。
1 | # 如果已经存在 a.img 别忘了回答 yes |
个人不建议一直用同一个被烧过的软盘跑,除非你保证每次都能把前面烧的内容覆盖掉。毕竟我们写入的方式是非截断的,并不会自动覆盖或重置掉后面的内容。
1 | run : |
如果你有按我上面说的重新打包一个 a.img.gz,你也可以维持原本的 makefile 不变。
这样我们每次改完 asm 就可以直接 make 啦。
或把上面的指令抄到 sh 文件里,加个可执行权限。
然后还有一个有趣的小工具,xygg 找到的,nasmfmt,一个格式化汇编代码的小工具。
1.5.2 源码分析
下面就是随书自带的源码了。
1 | org 07c00h ; where the code will be running |
程序第一行是一条伪指令,用来告诉编译器你后面的程序是从 07c00h
开始的(因为根据 Intel 80386,引导盘上的程序会被放到内存的 07c00h
处)。这会影响编译器对后面部分需要寻址的指令的编译。如果不加的话,编译器会认为程序是从
00000h 开始的,导致有些指令翻译成机器码后不能找到正确的地址。(比如
jmp $ 和 mov ax, BootMessage)
后面我们会分析反汇编后的代码,在反汇编后这个伪指令的作用会体现的更清晰。
P.S. 我一开始以为它真的会使编译出的 bin 文件前面有 31kb 的空白,23333。事实上编译出来的只是机器码的二进制程序,这个程序具体会被塞到哪里,并不是由编译器来决定的,编译器能做的只有把汇编翻译成机器码。
根据大一下学期学的 16 位实模式下 x86 汇编知识,我们知道 cs, ds, es, ss 是四个段寄存器。其中 cs:ip 指向现在正在执行的指令地址,ss 和 sp 是栈相关的(pop 使 sp 增加,push 使之减少)。es 和 ds 被用作数据段,es:[di], ds:[si]。
当然我们知道 32 位下是不一样的,比如 ip 变成了 eip 等。这暂时不重要,我们以后会学到的。这里只需要知道它是在初始化段寄存器就行。以及我们这个代码内使用的寄存器,实际上全是 16 位及以下的。
事实上,ds 在后面的代码中并没有用到,所以也可以不赋初值。
然后接下来调用了 display string 的"函数"。这个函数内部的实现我们待会说,先回顾一下 call 和 ret。call 做的,是把下一条指令的 eip 压入栈中,然后 jmp 到 DispStr 表示的偏移处。ret 则是把栈顶赋给 eip。
然后是 jmp $。后面还有另一处用到了
$$。对于这两个标志,官方文档中的解释是:
NASM supports two special tokens in expressions, allowing calculations to involve the current assembly position: the $ and $$ tokens. $ evaluates to the assembly position at the beginning of the line containing the expression; so you can code an infinite loop using JMP $. $$ evaluates to the beginning of the current section; so you can tell how far into the section you are by using ($-$$).
此处可以简单理解为当前位置偏移量和所在节偏移量。我们这个程序中只有一个所谓的节,所以可以理解为程序开始的位置,也就是 07c00h。
jmp $
的含义就是"跳转到当前指令"。这显然会是一个无限的循环。
最后三行都是我们学过的伪指令。db dw dd 是用来填放数据的,对应 byte, word, double word(字节,字,双字)。
$-$$ 可以理解为这条伪指令前面的部分已经占了多大。times 的意思是重复。显然的这个伪指令的意思就是填充 0 到 510 字节。
最后两个字节比较特殊,是 BIOS 识别引导扇区的依据,必须是 0xaa55。
如果不是 0xaa55 会发生什么?BIOS 会因为找不到启动引导盘而异常退出。你会在 bochs 收到一条这样的报错:[BIOS ] No bootable device.
接下来分析函数内的部分。
1 | DispStr: |
这个函数其实就是在调用中断处理程序。
前两行是在设置 bp
寄存器。事实上,变址寄存器并不是不能直接用立即数赋值,所以直接改成
mov bp, BootMessage 并没有什么问题。
es 前面设置过了。现在 es:bp
指向的是我们要显示的字符串的地址了。接下来的几行指令也是类似的,在设置调用的参数。然后
int 10h 调用中断处理程序。
我们大一上时学过这个。我们最熟悉的应该是
21h。大多数的中断例程都是通过 ah
来传递功能编号。我们这里调用的也许是 10h 号中断的 13h
号功能。
这个中断的相关信息我找到了这一篇 blog。可以参考一下,大概是差不多的意思。
xygg 太强了,什么都知道。官方文档在这里。
好像也没什么好解释的,就是调用了个 bios 里的中断处理程序显示了个字符串。
关于中断处理程序的组成,之前学过,但暂时还不需要,就不扯了。
1.5.3 反汇编
反汇编在这里是为了更好的理解代码的逻辑,观察代码实际编译的效果。
nasm 不仅提供了汇编的功能,也提供了反汇编的功能。你可以使用
ndisasm 进行反汇编。
具体的,我们使用下面的指令:
1 | # 直接执行 ndisasm 可以看到它的帮助 |
为什么我不建议加 -o 0x7c00 呢。因为它会使 call 和 jmp
指令反汇编出来的东西“看上去不一样”。实际上这两在这里都是相对寻址,但是如果你不仔细对比机器码看的话,很容易产生误解。而且不加这条的话,mov ax, BootMessage
的反汇编效果会更加明显,更能体现出 org 指令的作用。
这里就不给出反汇编的代码了,只用看前几行就行,因为它会把你填充的数据和 "hello os" 也当成指令反汇编。
1.5.4 bochs 调试
关于 debugger 相关的文档在这里。
也可以参考书上这个图。
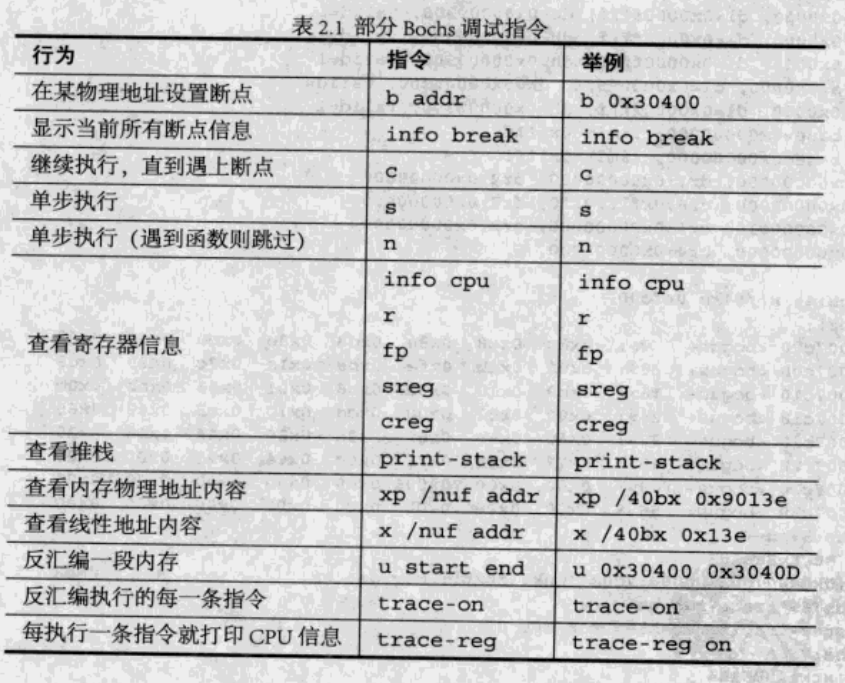
查看 gdt ldt 可以直接 info gdt。